3-1. Sample Spaces, Events, and Their Probabilities
样本空间和事件和概率
样本空间和事件 (概率论) - 文氏图(Venn Diagram) - 树形图(Tree Diagram)
概率(Probability)
1. Sample Spaces and Events
A random experiment is a mechanism that produces a definite outcome that cannot be predicted with certainty. The sample space associated with a random experiment is the set of all possible outcomes. An event is a subset of the sample space.
An event E is said to occur on a particular trial of the experiment if the outcome observed is an element of the set E.
EXAMPLE 1. Construct a sample space for the experiment that consists of tossing a single coin.
[ Solution ] S={H,T}
EXAMPLE 2. Construct a sample space for the experiment that consists of rolling a single die. Find the events that correspond to the phrases “an even number is rolled” and “a number greater than two is rolled.”
[ Solution ] S={1,2,3,4,5,6} , E1={2,4,6} , E2={3,4,5,6}
1-1. Venn Diagram
A graphical representation of a sample space and events is a Venn diagram

EXAMPLE 3. A random experiment consists of tossing two coins.
Construct a sample space for the situation that the coins are indistinguishable, such as two brand new pennies.
Construct a sample space for the situation that the coins are distinguishable, such as one a penny and the other a nickel.
[ Solution ]
two same coins : two head -> 2h, two tails -> 2t, 2 different faces : d =>S={2h,2t,d}
two different coins (penny, nickel) : S={hh,th,ht,tt}
1-2. Venn Diagram Plot in R
type of count data.
I want to develop a colorful (possibly semi-transparency at intersections) like the following Venn diagram.




[ 참고자료 - Venn Diagram ]
1-3. tree diagram
A device that can be helpful in identifying all possible outcomes of a random experiment, particularly one that can be viewed as proceeding in stages, is what is called a tree diagram.
EXAMPLE 4. Construct a sample space that describes all three-child families according to the genders of the children with respect to birth order.
[ Solution ] S={bbb,bbg,bgb,bgg,gbb,gbg,ggb,ggg} , g=girl ; b=boy

The line segments are called branches of the tree. The right ending point of each branch is called a node. The nodes on the extreme right are the final nodes; to each one there corresponds an outcome, as shown in the figure.
1-4. Tree Diagram in R






2. Probability
The probability of an outcome e in a sample space S is a number p between 0 and 1 that measures the likelihood that e will occur on a single trial of the corresponding random experiment. The value p=0 corresponds to the outcome e being impossible and the value p=1 corresponds to the outcome e being certain.
The probability of an event A is the sum of the probabilities of the individual outcomes of which it is composed. It is denoted p(A).
If an event E is E={e1,e2,...,ek}, then
P(E)=P(e1)+P(e2)+ ⋅⋅⋅ +P(ek)
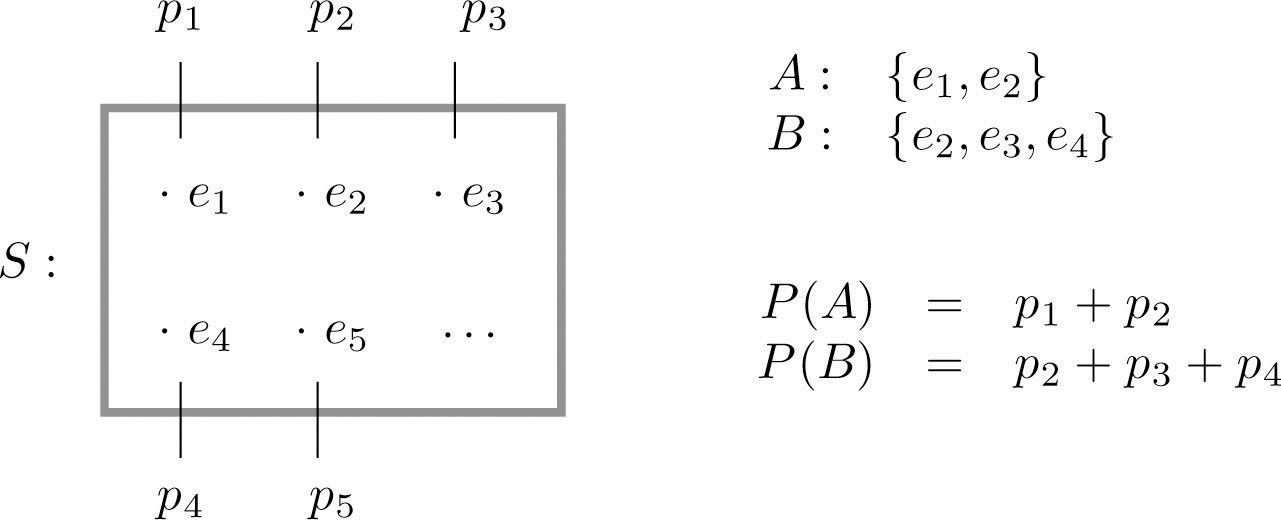
EXAMPLE 5. A coin is called “balanced” or “fair” if each side is equally likely to land up. Assign a probability to each outcome in the sample space for the experiment that consists of tossing a single fair coin.
[ Solution ] S={H,T} , P(H)=P(T)=1/2
EXAMPLE 6. A die is called “balanced” or “fair” if each side is equally likely to land on top. Assign a probability to each outcome in the sample space for the experiment that consists of tossing a single fair die. Find the probabilities of the events E : “an even number is rolled” and T : “a number greater than two is rolled.”
[ Solution ] S={1,2,3,4,5,6}
E={2,4,6} , P(E)=3/6=1/2
T={3,4,5,6} , P(T)=4/6=2/3
EXAMPLE 7. Two fair coins are tossed. Find the probability that the coins match, i.e., either both land heads or both land tails.
[ Solution ]
identical coins : S={2h,2t,d} , E={2h,2t} => P(E)=2/3
two different coins : St={2h,ht,th,2t} , Et={2h,2t} => P(Et)=2/4=1/2
[ Solution 1 ]
[ Solution 2 ]
EXAMPLE 8. The breakdown of the student body in a local high school according to race and ethnicity is 51% white, 27% black, 11% Hispanic, 6% Asian, and 5% for all others. A student is randomly selected from this high school. (To select “randomly” means that every student has the same chance of being selected.) Find the probabilities of the following events:

B : the student is black,
M : the student is minority (that is, not white),
N : the student is not black.
[ Solution ]
P(B)=P(b)=0.27
P(M)=1−P(w)=1−0.51=0.49
P(N)=1−P(b)=1−0.27=0.73
EXAMPLE 9. The student body in the high school considered in "Example 8" may be broken down into ten categories as follows: 25% white male, 26% white female, 12% black male, 15% black female, 6% Hispanic male, 5% Hispanic female, 3% Asian male, 3% Asian female, 1% male of other minorities combined, and 4% female of other minorities combined. A student is randomly selected from this high school. Find the probabilities of the following events:

B : the student is black,
MF : the student is minority female,
FN : the student is female and is not black.
[ Solution ]
P(B)=P(bm)+P(bf)=0.12+0.15=0.27
P(MF)=P(bf)+P(hf)+P(af)+P(of)=0.15+0.05+0.03+0.04=0.27
P(FN)=P(wf)+P(hf)+P(af)+P(of)=0.26+0.05+0.03+0.04=0.38
样本空间和事件 (概率论) - 文氏图(Venn Diagram) - 树形图(Tree Diagram)
概率(Probability)
Last updated