# 3-2. Complements, Intersections,and Unions
{% file src="/files/-Ly1r19pm2LTBLg3l2sw" %}
Installation of Rstat Package (Korean)
{% endfile %}
{% file src="/files/-Ly1qkTEPS8A3AoNP9km" %}
Installation of Rstat Package (Chinese)
{% endfile %}
{% file src="/files/-Ly1lRIHVK3zrp\_nh2PS" %}
Rstat.zip
{% endfile %}
## 1. Complements
> *The* **complement of an event** $$A$$ *in a sample space* $$S$$ , *denoted* $$A^c$$ , *is the collection of all outcomes in* $$S$$*that are not elements of the set* *A*. *It corresponds to negating any description in words of the event* $$A$$.
**EXAMPLE 10.** Two events connected with the experiment of rolling a single die are $$E$$ : “the number rolled is even” and $$T$$ : “the number rolled is greater than two.” Find the complement of each.
**\[ Solution ]**
$$S = {1,2,3,4,5,6}$$
$$E = {2,4,6}$$ , $$T = {3,4,5,6}$$
$$=> E^c = {1,3,5}$$ , and $$T^c = {1,2}$$
* Using **prob** Package : `setdiff()`
{% tabs %}
{% tab title="R Source" %}
```
library(prob)
# 1. Sample Space
S <- rolldie(1); S
# 2. E and E Complement
E <- subset(S, X1 %% 2 == 0); E
Ec <- setdiff(S, E); Ec
# 3. T and T Complement
T <- subset(S, X1 > 2); T
Tc <- setdiff(S, T); Tc
```
{% endtab %}
{% tab title="Sample Space" %}
```
> # 1. Sample Space
> S <- rolldie(1); S
## X1
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
```
{% endtab %}
{% tab title="E and Ec" %}
```
> # 2. E and E Complement
> E <- subset(S, X1 %% 2 == 0); E
## X1
## 2 2
## 4 4
## 6 6
> Ec <- setdiff(S, E); Ec
## [1] 1 3 5
```
{% endtab %}
{% tab title="T and Tc" %}
```
> # 3. T and T Complement
> T <- subset(S, X1 > 2); T
## X1
## 3 3
## 4 4
## 5 5
## 6 6
> Tc <- setdiff(S, T); Tc
## [1] 1 2
```
{% endtab %}
{% endtabs %}
* Using **Rstat** Package : `setdiff2()`
{% tabs %}
{% tab title="R Source" %}
```
library(Rstat)
# 1. Sample Space
S <- rolldie2(1); element(S)
# 2. E and E Complement
E <- subset(S, X1 %% 2 == 0); element(E)
Ec <- setdiff2(S, E); element(Ec)
# 3. T and T Complement
T <- subset(S, X1 > 2); element(T)
Tc <- setdiff2(S, T); element(Tc)
```
{% endtab %}
{% tab title="Result" %}
```
> # 1. Sample Space
> S <- rolldie2(1); element(S)
## (1) (2) (3) (4) (5) (6)
>
> # 2. E and E Complement
> E <- subset(S, X1 %% 2 == 0); element(E)
## (2) (4) (6)
> Ec <- setdiff2(S, E); element(Ec)
## (1) (3) (5)
>
> # 3. T and T Complement
> T <- subset(S, X1 > 2); element(T)
## (3) (4) (5) (6)
> Tc <- setdiff2(S, T); element(Tc)
## (1) (2)
```
{% endtab %}
{% endtabs %}
> **Probability Rule for Complements** \
> $$P(A^c)=1−P(A)$$
**EXAMPLE 11** . Find the probability that at least one heads will appear in five tosses of a fair coin.
**\[ Solution ]**
* 32 Outcomes for five tosses of coin : $$2^5 = 32$$
* $$O^c={ttttt}$$
* $$P(O) = 1- P(O^c) = 1 - 1/32 = 31/32$$
Using **prob** Package : `Prob()`
{% tabs %}
{% tab title="R Source" %}
```
library(prob)
# 1. Sample Space and Number of Outcoms
S <- tosscoin(5, makespace = TRUE); S
nrow(S)
# 2. O Complement and P(Oc)
Oc <- subset(S, as.numeric(toss1) + as.numeric(toss2)
+ as.numeric(toss3) + as.numeric(toss4)
+ as.numeric(toss5) == 10)
Oc
# or
counth <- function(x) sum(x=="H") # Count the number of "H"
Oc <- subset(S, apply(S, 1, counth) == 5); Oc
# 3. O and P(O)
O <- setdiff(S, Oc); O
Prob(O)
```
{% endtab %}
{% tab title="Sample Space and # of Outcomes" %}
```
> # 1. Sample Space and Number of Outcoms
> S <- tosscoin(5, makespace = TRUE); S
## toss1 toss2 toss3 toss4 toss5 probs
## 1 H H H H H 0.03125
## 2 T H H H H 0.03125
## 3 H T H H H 0.03125
## 4 T T H H H 0.03125
## 5 H H T H H 0.03125
## 6 T H T H H 0.03125
## 7 H T T H H 0.03125
## 8 T T T H H 0.03125
## 9 H H H T H 0.03125
## 10 T H H T H 0.03125
## 11 H T H T H 0.03125
## 12 T T H T H 0.03125
## 13 H H T T H 0.03125
## 14 T H T T H 0.03125
## 15 H T T T H 0.03125
## 16 T T T T H 0.03125
## 17 H H H H T 0.03125
## 18 T H H H T 0.03125
## 19 H T H H T 0.03125
## 20 T T H H T 0.03125
## 21 H H T H T 0.03125
## 22 T H T H T 0.03125
## 23 H T T H T 0.03125
## 24 T T T H T 0.03125
## 25 H H H T T 0.03125
## 26 T H H T T 0.03125
## 27 H T H T T 0.03125
## 28 T T H T T 0.03125
## 29 H H T T T 0.03125
## 30 T H T T T 0.03125
## 31 H T T T T 0.03125
## 32 T T T T T 0.03125
> nrow(S)
## [1] 32
```
{% endtab %}
{% tab title="Oc and P(Oc)" %}
```
> # 2. O Complement and P(Oc)
> Oc <- subset(S, as.numeric(toss1) + as.numeric(toss2)
+ + as.numeric(toss3) + as.numeric(toss4)
+ + as.numeric(toss5) == 10)
> Oc
## toss1 toss2 toss3 toss4 toss5 probs
## 32 T T T T T 0.03125
>
> # or
> counth <- function(x) sum(x=="H") # Count the number of "H"
> Oc <- subset(S, apply(S, 1, counth) == 5) ; Oc
## toss1 toss2 toss3 toss4 toss5 probs
## 1 H H H H H 0.03125
```
{% endtab %}
{% tab title="O and P(O)" %}
```
> # 3. O and P(O)
> O <- setdiff(S, Oc); O
## toss1 toss2 toss3 toss4 toss5 probs
## 1 H H H H H 0.03125
## 2 T H H H H 0.03125
## 3 H T H H H 0.03125
## 4 T T H H H 0.03125
## 5 H H T H H 0.03125
## 6 T H T H H 0.03125
## 7 H T T H H 0.03125
## 8 T T T H H 0.03125
## 9 H H H T H 0.03125
## 10 T H H T H 0.03125
## 11 H T H T H 0.03125
## 12 T T H T H 0.03125
## 13 H H T T H 0.03125
## 14 T H T T H 0.03125
## 15 H T T T H 0.03125
## 16 T T T T H 0.03125
## 17 H H H H T 0.03125
## 18 T H H H T 0.03125
## 19 H T H H T 0.03125
## 20 T T H H T 0.03125
## 21 H H T H T 0.03125
## 22 T H T H T 0.03125
## 23 H T T H T 0.03125
## 24 T T T H T 0.03125
## 25 H H H T T 0.03125
## 26 T H H T T 0.03125
## 27 H T H T T 0.03125
## 28 T T H T T 0.03125
## 29 H H T T T 0.03125
## 30 T H T T T 0.03125
## 31 H T T T T 0.03125
> Prob(O)
## [1] 0.96875
```
{% endtab %}
{% endtabs %}
* Using **Rstat** Package : `pprt()`
{% tabs %}
{% tab title="R Source" %}
```
library(Rstat)
# 1. Sample Space and Number of Outcoms
S <- tosscoin2(5)
S <- S[order(S$X1,S$X2,S$X3,S$X4,S$X5),]
element(S, 8)
# 2. O Complement and P(Oc)
counth <- function(x) sum(x=="H") # Count the number of "H"
Oc <- subset(S, apply(S, 1, counth) == 5); element(Oc, 6)
pprt(Oc, nrow(S))
# 3. O and P(O)
O <- setdiff2(S, Oc)
pprt(O, nrow(S))
```
{% endtab %}
{% tab title="Result" %}
```
> # 1. Sample Space and Number of Outcoms
> S <- tosscoin2(5)
> S <- S[order(S$X1,S$X2,S$X3,S$X4,S$X5),]
> element(S, 8)
## (H,H,H,H,H) (H,H,H,H,T) (H,H,H,T,H) (H,H,H,T,T) (H,H,T,H,H) (H,H,T,H,T) (H,H,T,T,H) (H,H,T,T,T)
## (H,T,H,H,H) (H,T,H,H,T) (H,T,H,T,H) (H,T,H,T,T) (H,T,T,H,H) (H,T,T,H,T) (H,T,T,T,H) (H,T,T,T,T)
## (T,H,H,H,H) (T,H,H,H,T) (T,H,H,T,H) (T,H,H,T,T) (T,H,T,H,H) (T,H,T,H,T) (T,H,T,T,H) (T,H,T,T,T)
## (T,T,H,H,H) (T,T,H,H,T) (T,T,H,T,H) (T,T,H,T,T) (T,T,T,H,H) (T,T,T,H,T) (T,T,T,T,H) (T,T,T,T,T)
>
> # 2. O Complement and P(Oc)
> counth <- function(x) sum(x=="H") # Count the number of "H"
> Oc <- subset(S, apply(S, 1, counth) == 5); element(Oc, 6)
## (H,H,H,H,H)
> pprt(Oc, nrow(S))
## P(Oc) = 1 / 32 = 0.03125
>
> # 3. O and P(O)
> O <- setdiff2(S, Oc)
> pprt(O, nrow(S))
## P(O) = 31 / 32 = 0.96875
```
{% endtab %}
{% endtabs %}
## 2. Intersection of Events
> *The* **intersection of events** *A* *and* *B*, *denoted* *A* ∩ *B*, *is the collection of all outcomes that are elements of both of the sets* *A* *and* *B*. *It corresponds to combining descriptions of the two events using the word “and.”* ( A ∩ B )

**EXAMPLE 12.** In the experiment of rolling a single die, find the intersection E∩T of the events *E* : “the number rolled is even” and *T* : “the number rolled is greater than two.”
**\[ Solution ]**
$$S = {1,2,3,4,5,6}$$
$$E = {2,4,6}$$ , $$T = {3,4,5,6}$$ $$=> E ∩ T = {4, 6}$$
* in **prob** Package : `intersect()`
{% tabs %}
{% tab title="R Source" %}
```
library(prob)
# 1. Sample Space
S <- rolldie(1); S
# 2. E and E Complement
E <- subset(S, X1 %% 2 == 0); E
# 3. T and T Complement
T <- subset(S, X1 > 2); T
# 4. Intersect of E and T
intersect(E,T)
```
{% endtab %}
{% tab title="Sample Space" %}
```
> # 1. Sample Space
> S <- rolldie(1); S
## X1
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
```
{% endtab %}
{% tab title="E" %}
```
> # 2. E and E Complement
> E <- subset(S, X1 %% 2 == 0); E
## X1
## 2 2
## 4 4
## 6 6
```
{% endtab %}
{% tab title="T" %}
```
> # 3. T and T Complement
> T <- subset(S, X1 > 2); T
## X1
## 3 3
## 4 4
## 5 5
## 6 6
```
{% endtab %}
{% tab title="E ∩ T" %}
```
> # 4. Intersect of E and T
> intersect(E,T)
## [1] 4 6
```
{% endtab %}
{% endtabs %}
* in **Rstat** Package : `intersect2()`
{% tabs %}
{% tab title="R Source" %}
```
library(Rstat)
# 1. Sample Space
S <- rolldie2(1); element(S)
# 2. E and E Complement
E <- subset(S, X1 %% 2 == 0); element(E)
# 3. T and T Complement
T <- subset(S, X1 > 2); element(T)
# 4. Intersect of E and T
ET <- intersect2(E,T); element(ET)
```
{% endtab %}
{% tab title="Result" %}
```
> # 1. Sample Space
> S <- rolldie2(1); element(S)
## (1) (2) (3) (4) (5) (6)
>
> # 2. E and E Complement
> E <- subset(S, X1 %% 2 == 0); element(E)
## (2) (4) (6)
>
> # 3. T and T Complement
> T <- subset(S, X1 > 2); element(T)
## (3) (4) (5) (6)
>
> # 4. Intersect of E and T
> ET <- intersect2(E,T); element(ET)
## (4) (6)
```
{% endtab %}
{% endtabs %}
**EXAMPLE 13.** A single die is rolled.
1. Suppose *the die is fair*. Find the probability that the number rolled is both even and greater than two.
2. Suppose the die has been “loaded” so that $$P(1)=1∕12$$ , $$P(6)=3∕12$$ , and the remaining four outcomes are equally likely with one another. Now find the probability that the number rolled is **both even and greater than two**.
**\[ Solution ]**
$$S={1,2,3,4,5,6}, A = {2,4,6} , B={3,4,5,6}, A ∩ B ={4, 6}$$
1. $$P(A ∩ B) =P{4, 6} = P(4) + P(6) = 2/6 = 1/3$$
2. $$P(A ∩ B) =P{4, 6} = P(4) + P(6)$$ \
$$P(4) = ( 1 - 1/12 - 3/12) /4 = 2/12 = 1/6$$ \
$$=> P(4,6) = 1/6 + 3/12 = 5/12$$
###
### \* Probability Rule for Mutually Exclusive Events
> *Events* *A* *and* *B* *are* **mutually exclusive** *if they have no elements in common.*
> Events *A* and *B* are **mutually exclusive** if and only if
>
> $$P(A∩B)=0$$
**EXAMPLE 14.** In the experiment of rolling a single die, find three choices for an event $$A$$ so that the events $$A$$ and $$E$$: “the number rolled is even” are mutually exclusive.
**\[ Solution ]**
Since $$E={2,4,6}$$ and we want $$A$$ to have no elements in common with $$E$$ , any event that does not contain any even number will do. Three choices are $${1,3,5}$$ (the complement $$E^c$$ , the odds), $${1,3}$$ , and $${5}$$ .
* Using **Rstat** Package
{% tabs %}
{% tab title="R Source" %}
```
library(Rstat)
# 1. Sample Space
S <- rolldie2(1); element(S)
# 2. E
E <- subset(S, X1 %% 2 == 0); element(E)
```
{% endtab %}
{% tab title="Result" %}
```
> # 1. Sample Space
> S <- rolldie2(1); element(S)
## (1) (2) (3) (4) (5) (6)
>
> # 2. E and E Complement
> E <- subset(S, X1 %% 2 == 0); element(E)
## (2) (4) (6)
```
{% endtab %}
{% endtabs %}
## 3. Union of Events
> *The* **union of events** *A* *and* *B*, *denoted* $$A ∪ B$$ , *is the collection of all outcomes that are elements of one or the other of the sets* *A* *and* *B*, *or of both of them. It corresponds to combining descriptions of the two events using the word “or.”*
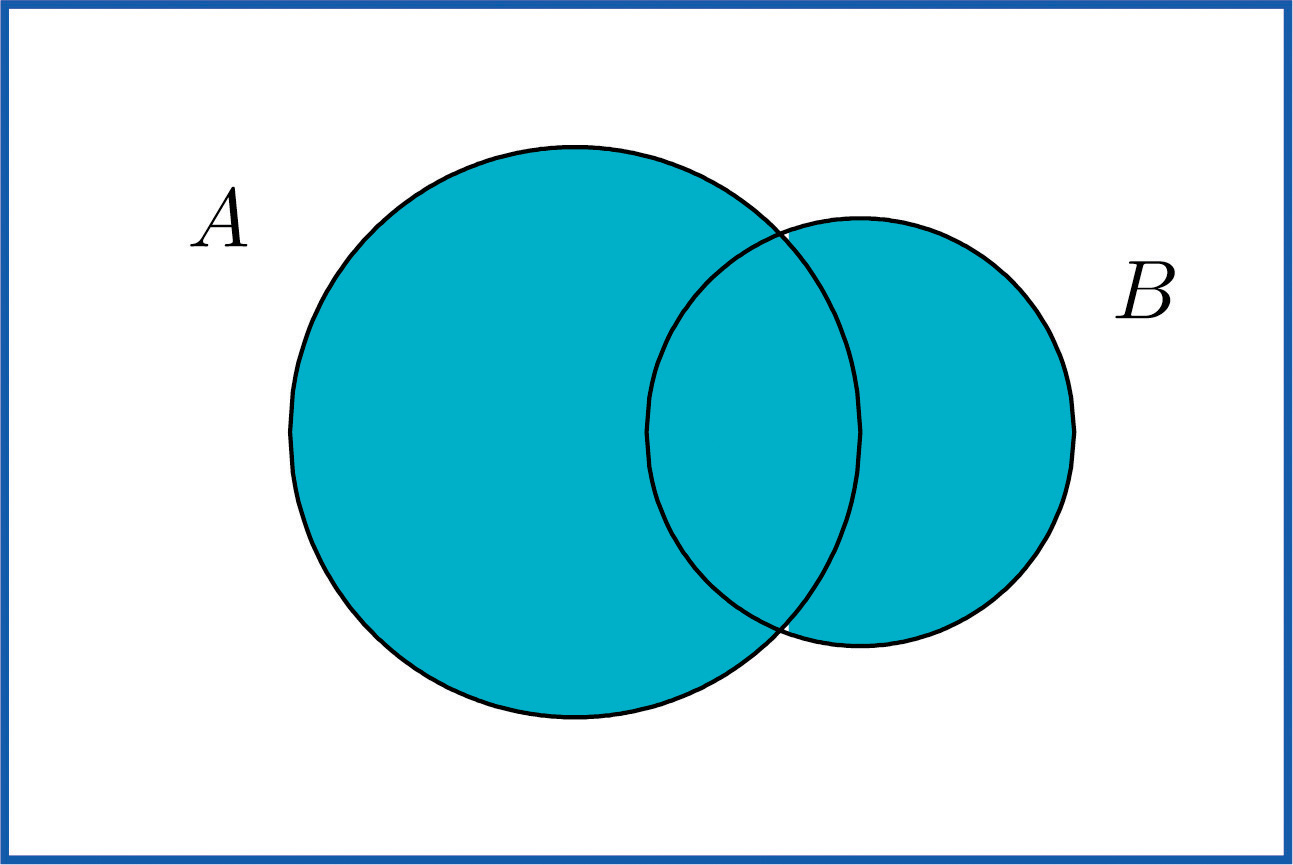
**EXAMPLE 15.** In the experiment of rolling a single die, find the union of the events $$E$$ : “the number rolled is even” and $$T$$ : “the number rolled is greater than two.”
**\[ Solution ]**
Since the outcomes that are in either $$E={2,4,6}$$ or $$T={3,4,5,6}$$ (or both) are 2, 3, 4, 5, and 6, $$E∪T={2,3,4,5,6}$$ . Note that an outcome such as 4 that is in both sets is still listed only once (although strictly speaking it is not incorrect to list it twice).
In words the union is described by “the number rolled is even or is greater than two.” Every number between one and six except the number one is either even or is greater than two, corresponding to $$E ∪ T$$ given above.
* in **prob** Package : `union()`
{% tabs %}
{% tab title="R Source" %}
```
library(prob)
# 1. Sample Space
S <- rolldie(1); S
# 2. E
E <- subset(S, X1 %% 2 == 0); E
# 3. T
T <- subset(S, X1 > 2); T
# 4. Union of E and T
union(E,T)
```
{% endtab %}
{% tab title="Sample Space" %}
```
> # 1. Sample Space
> S <- rolldie(1); S
## X1
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
```
{% endtab %}
{% tab title="E" %}
```
> # 2. E
> E <- subset(S, X1 %% 2 == 0); E
## X1
## 2 2
## 4 4
## 6 6
```
{% endtab %}
{% tab title="T" %}
```
> # 3. T
> T <- subset(S, X1 > 2); T
## X1
## 3 3
## 4 4
## 5 5
## 6 6
```
{% endtab %}
{% tab title="E ∪ T" %}
```
> # 4. Union of E and T
> union(E,T)
## [1] 2 3 4 5 6
```
{% endtab %}
{% endtabs %}
* in **Rstat** Package : `union2()`
{% tabs %}
{% tab title="R Source" %}
```
library(Rstat)
# 1. Sample Space
S <- rolldie2(1); element(S)
# 2. E
E <- subset(S, X1 %% 2 == 0); element(E)
# 3. T
T <- subset(S, X1 > 2); element(T)
# 4. Union of E and T
ET <- union2(E,T)
ET <- ET[order(ET$X1),]
element(data.frame(ET))
```
{% endtab %}
{% tab title="Result" %}
```
> # 1. Sample Space
> S <- rolldie2(1); element(S)
## (1) (2) (3) (4) (5) (6)
>
> # 2. E
> E <- subset(S, X1 %% 2 == 0); element(E)
## (2) (4) (6)
>
> # 3. T
> T <- subset(S, X1 > 2); element(T)
## (3) (4) (5) (6)
>
> # 4. Union of E and T
> ET <- union2(E,T)
> ET <- ET[order(ET$X1),]
> element(data.frame(ET))
## (2) (3) (4) (5) (6)
```
{% endtab %}
{% endtabs %}
**EXAMPLE 16.** A two-child family is selected at random. Let $$B$$ denote the event that at least one child is a boy, let $$D$$ denote the event that the genders of the two children differ, and let $$M$$ denote the event that the genders of the two children match. Find $$B ∪ D$$ and $$B∪M$$ .
**\[ Solution ]**
A sample space for this experiment is $$S={bb,bg,gb,gg}$$ , where the first letter denotes the gender of the firstborn child and the second letter denotes the gender of the second child. The events $$B$$, $$D$$, and $$M$$ are
$$B={bb,bg,gb}$$ $$D={bg,gb}$$ $$M={bb,gg}$$
Each outcome in $$D$$ is already in $$B$$, so the outcomes that are in at least one or the other of the sets $$B$$ and $$D$$ is just the set $$B$$ itself: $$B∪D={bb,bg,gb}=B$$ .
Every outcome in the whole sample space *S* is in at least one or the other of the sets $$B$$ and $$M$$, so $$B∪M={bb,bg,gb,gg}=S$$ .
* Using **prob** Package
{% tabs %}
{% tab title="R Source" %}
```
library(prob)
# 1. Sample Space
S <- data.frame(c1=c("b","b","g","g"), c2=c("b","g","b","g")); S
# 2. B, D, M
B <- subset(S, as.numeric(c1) + as.numeric(c2) < 4); B
D <- subset(S, c1 != c2); D
M <- subset(S, c1 == c2); M
# 3. B∪D and B∪M
union(B, D)
union(B, M)
```
{% endtab %}
{% tab title="Sample Space" %}
```
> # 1. Sample Space
> S <- data.frame(c1=c("b","b","g","g"), c2=c("b","g","b","g")); S
## c1 c2
## 1 b b
## 2 b g
## 3 g b
## 4 g g
```
{% endtab %}
{% tab title="B, D, M" %}
```
> # 2. B, D, M
> B <- subset(S, as.numeric(c1) + as.numeric(c2) < 4); B
## c1 c2
## 1 b b
## 2 b g
## 3 g b
>
> D <- subset(S, c1 != c2); D
## c1 c2
## 2 b g
## 3 g b
>
> M <- subset(S, c1 == c2); M
## c1 c2
## 1 b b
## 4 g g
```
{% endtab %}
{% tab title="B∪D and B∪M" %}
```
> # 3. B∪D and B∪M
> union(B, D)
## c1 c2
## 1 b b
## 2 b g
## 3 g b
>
> union(B, M)
## c1 c2
## 1 b b
## 2 b g
## 3 g b
## 4 g g
```
{% endtab %}
{% endtabs %}
* Using **Rstat** Package
{% tabs %}
{% tab title="R Source" %}
```
library(Rstat)
# 1. Sample Space
S <- data.frame(c1=c("b","b","g","g"), c2=c("b","g","b","g")); element(S)
# 2. B, D, M
B <- subset(S, as.numeric(c1) + as.numeric(c2) < 4); element(B)
D <- subset(S, c1 != c2); element(D)
M <- subset(S, c1 == c2); element(M)
# 3. B∪D and B∪M
BuD <- union(B, D); element(BuD)
BuM <- union(B, M); element(BuM)
```
{% endtab %}
{% tab title="Result" %}
```
> # 1. Sample Space
> S <- data.frame(c1=c("b","b","g","g"), c2=c("b","g","b","g")); element(S)
## (b,b) (b,g) (g,b) (g,g)
>
> # 2. B, D, M
> B <- subset(S, as.numeric(c1) + as.numeric(c2) < 4); element(B)
## (b,b) (b,g) (g,b)
> D <- subset(S, c1 != c2); element(D)
## (b,g) (g,b)
> M <- subset(S, c1 == c2); element(M)
## (b,b) (g,g)
>
> # 3. B∪D and B∪M
> BuD <- union(B, D); element(BuD)
## (b,b) (b,g) (g,b)
> BuM <- union(B, M); element(BuM)
## (b,b) (b,g) (g,b) (g,g)
```
$$P(B ∪D) = P(B) = {bb, bg, gb }$$ ,
$$P(B ∪M) = P(S)={bb, bg, gb, gg}$$
{% endtab %}
{% endtabs %}
> **Additive Rule of Probability**
>
> $$P(A∪B)=P(A)+P(B)−P(A∩B)$$
**EXAMPLE 17.** Two fair dice are thrown. Find the probabilities of the following events:
1. both dice show a four
2. at least one die shows a four
**\[ Solution ]**
As was the case with tossing two identical coins, actual experience dictates that for the sample space to have equally likely outcomes we should list outcomes as if we could distinguish the two dice. We could imagine that one of them is red and the other is green. Then any outcome can be labeled as a pair of numbers as in the following display, where the first number in the pair is the number of dots on the top face of the green die and the second number in the pair is the number of dots on the top face of the red die.
```
11 12 13 14 15 16
21 22 23 24 25 26
31 32 33 34 35 36
41 42 43 44 45 46
51 52 53 54 55 56
61 62 63 64 65 66
```
1. There are 36 equally likely outcomes, of which exactly one corresponds to two fours, so the probability of a pair of fours is 1/36.
2. From the table we can see that there are 11 pairs that correspond to the event in question: the six pairs in the fourth row (the green die shows a four) plus the additional five pairs other than the pair 44, already counted, in the fourth column (the red die is four), so the answer is 11/36. To see how the formula gives the same number, let $$A\_G$$ denote the event that the green die is a four and let $$A\_R$$ denote the event that the red die is a four. Then clearly by counting we get $$P(A\_G)=6∕36$$ and $$P(A\_R)=6∕36$$. Since $$A\_G∩A\_R={44}$$ , $$P(A\_G∩A\_R)=1∕36$$ ; this is the computation in part (a), of course. Thus by the Additive Rule of Probability,\
\
$$P(A\_G∪A\_R)=P(A\_G)+P(A\_R)−P(A\_G−A\_R)=\frac{6}{36}+\frac{6}{36}−\frac{1}{36}=\frac{11}{36}$$
* Using **prob** Package
{% tabs %}
{% tab title="R Source" %}
```
library(prob)
# 1. Sample Space and Number of Outcoms
S <- rolldie(2, makespace = TRUE); S
# 2. Both dice show a four
A <- subset(S, X1 == 4 & X2 == 4); A
Prob(A)
# 3. at least one die shows a four
Bc <- subset(S, X1 != 4 & X2 != 4)
B <- setdiff(S, Bc); B
Prob(B)
```
{% endtab %}
{% tab title="Sample Space" %}
```
> # 1. Sample Space and Number of Outcoms
> S <- rolldie(2, makespace = TRUE); S
## X1 X2 probs
## 1 1 1 0.02777778
## 2 2 1 0.02777778
## 3 3 1 0.02777778
## 4 4 1 0.02777778
## 5 5 1 0.02777778
## 6 6 1 0.02777778
## 7 1 2 0.02777778
## 8 2 2 0.02777778
## 9 3 2 0.02777778
## 10 4 2 0.02777778
## 11 5 2 0.02777778
## 12 6 2 0.02777778
## 13 1 3 0.02777778
## 14 2 3 0.02777778
## 15 3 3 0.02777778
## 16 4 3 0.02777778
## 17 5 3 0.02777778
## 18 6 3 0.02777778
## 19 1 4 0.02777778
## 20 2 4 0.02777778
## 21 3 4 0.02777778
## 22 4 4 0.02777778
## 23 5 4 0.02777778
## 24 6 4 0.02777778
## 25 1 5 0.02777778
## 26 2 5 0.02777778
## 27 3 5 0.02777778
## 28 4 5 0.02777778
## 29 5 5 0.02777778
## 30 6 5 0.02777778
## 31 1 6 0.02777778
## 32 2 6 0.02777778
## 33 3 6 0.02777778
## 34 4 6 0.02777778
## 35 5 6 0.02777778
## 36 6 6 0.02777778
```
{% endtab %}
{% tab title="# 1." %}
```
> # 2. Both dice show a four
> A <- subset(S, X1 == 4 & X2 == 4); A
## X1 X2 probs
## 22 4 4 0.02777778
> Prob(A)
## [1] 0.02777778
```
{% endtab %}
{% tab title="# 2." %}
```
> # 3. at least one die shows a four
> Bc <- subset(S, X1 != 4 & X2 != 4)
> B <- setdiff(S, Bc); B
## X1 X2 probs
## 4 4 1 0.02777778
## 10 4 2 0.02777778
## 16 4 3 0.02777778
## 19 1 4 0.02777778
## 20 2 4 0.02777778
## 21 3 4 0.02777778
## 22 4 4 0.02777778
## 23 5 4 0.02777778
## 24 6 4 0.02777778
## 28 4 5 0.02777778
## 34 4 6 0.02777778
> Prob(B)
## [1] 0.3055556
```
{% endtab %}
{% endtabs %}
* Using **Rstat** Package
{% tabs %}
{% tab title="R Source" %}
```
library(Rstat)
# 1. Sample Space and Number of Outcoms
S <- rolldie2(2);
S <- S[order(S$X1, S$X2), ]
element(S, 6)
# 2. Both dice show a four
A <- subset(S, X1 == 4 & X2 == 4); element(A)
pprt(A, nrow(S))
# 3. at least one die shows a four
Bc <- subset(S, X1 != 4 & X2 != 4)
B <- setdiff2(S, Bc); element(B, 6)
pprt(B, nrow(S))
```
{% endtab %}
{% tab title="Result" %}
```
> # 1. Sample Space and Number of Outcoms
> S <- rolldie2(2);
> S <- S[order(S$X1, S$X2), ]
> element(S, 6)
## (1,1) (1,2) (1,3) (1,4) (1,5) (1,6)
## (2,1) (2,2) (2,3) (2,4) (2,5) (2,6)
## (3,1) (3,2) (3,3) (3,4) (3,5) (3,6)
## (4,1) (4,2) (4,3) (4,4) (4,5) (4,6)
## (5,1) (5,2) (5,3) (5,4) (5,5) (5,6)
## (6,1) (6,2) (6,3) (6,4) (6,5) (6,6)
>
> # 2. Both dice show a four
> A <- subset(S, X1 == 4 & X2 == 4); element(A)
## (4,4)
> pprt(A, nrow(S))
## P(A) = 1 / 36 = 0.02777778
>
> # 3. at least one die shows a four
> Bc <- subset(S, X1 != 4 & X2 != 4)
> B <- setdiff2(S, Bc); element(B, 6)
## (1,4) (2,4) (3,4) (4,1) (4,2) (4,3)
## (4,4) (4,5) (4,6) (5,4) (6,4)
> pprt(B, nrow(S))
## P(B) = 11 / 36 = 0.3055556
```
{% endtab %}
{% endtabs %}
**EXAMPLE 18.** A tutoring service specializes in preparing adults for high school equivalence tests. Among all the students seeking help from the service, 63% need help in mathematics, 34% need help in English, and 27% need help in both mathematics and English. What is the percentage of students who need help in either mathematics or English?
**\[ Solution ]**
Imagine selecting a student at random, that is, in such a way that every student has the same chance of being selected. Let $$M$$denote the event “the student needs help in mathematics” and let $$E$$ denote the event “the student needs help in English.” The information given is that $$P(M)=0.63$$ , $$P(E)=0.34$$ , and $$P(M∩E)=0.27$$ . The Additive Rule of Probability gives
$$P(M∪E)=P(M)+P(E)−P(M∩E)=0.63+0.34−0.27=0.70$$
**EXAMPLE 19.** Volunteers for a disaster relief effort were classified according to both specialty ( $$C$$ : construction, $$E$$: education, $$M$$: medicine) and language ability ( $$S$$ : speaks a single language fluently, $$T$$ : speaks two or more languages fluently). The results are shown in the following *two-way classification* *table*:

The first row of numbers means that 12 volunteers whose specialty is construction speak a single language fluently, and 1 volunteer whose specialty is construction speaks at least two languages fluently. Similarly for the other two rows.
A volunteer is selected at random, meaning that each one has an equal chance of being chosen. Find the probability that:
1. his specialty is medicine and he speaks two or more languages;
2. either his specialty is medicine or he speaks two or more languages;
3. his specialty is something other than medicine.
**\[ Solution ]**
When information is presented in a two-way classification table it is typically convenient to adjoin to the table the row and column totals, to produce a new table like this:
| | Language Ability | | |
| --------- | ---------------- | --- | ----- |
| Specialty | *S* | *T* | Total |
| *C* | 12 | 1 | 13 |
| *E* | 4 | 3 | 7 |
| *M* | 6 | 2 | 8 |
| Total | 22 | 6 | 28 |
1. The probability sought is $$P(M∩T)$$ . The table shows that there are 2 such people, out of 28 in all, hence $$P(M∩T)=2∕28≈0.07$$ or about a 7% chance.
2. The probability sought is P(M∪T).P(M∪T). The third row total and the grand total in the sample give $$P(M)=8∕28$$ . The second column total and the grand total give $$P(T)=6∕28$$ . Thus using the result from part (a),\
$$P(M∪T)=P(M)+P(T)−P(M∩T)=8/28+6/28−2/28=12/28≈0.43$$
or about a 43% chance./
3. This probability can be computed in two ways. Since the event of interest can be viewed as the event *C* ∪ *E* and the events *C* and *E* are mutually exclusive, the answer is, using the first two row totals,\
$$P(C∪E)=P(C)+P(E)−P(C∩E)=13/28+7/28−0/28=20/28≈0.71$$
On the other hand, the event of interest can be thought of as the complement $$M^c$$ of $$M$$, hence using the value of $$P(M)$$ computed in part (b),\
$$P(M^c)=1−P(M)=1−8/28=20/28≈0.71$$
as before.
**EXAMPLE 20.** Four fair dice are thrown. Find the probabilities of the following events:
1. $$A$$ = sum of four dice is greater than or equal to 15.
2. $$B$$ = at least one die shows a six
3. $$C$$ = at least one die shows a one
4. $$P(A∩B), P(A∩C), P(B∩C), P(A∩B∩C)$$
5. $$P(A∪B), P(A∪C), P(B∪C), P(A∪B∪C)$$
6. $$P(A∩B^c), P(A^c∩B^c), P(A∩B∩C^c), P(A∩B^c∩C)$$.
And draw a Venn Diagram.
{% tabs %}
{% tab title="R Source" %}
```
library(Rstat)
# 0. Sample Space and Number of Outcoms
S <- rolldie2(4); N <- nrow(S)
# 1. sum of four dice is greater than or equal to 15
A <- subset(S, X1+X2+X3+X4 >= 15)
pprt(A, N)
# 2. at least one die shows a six
B <- subset(S, apply(S, 1, max) == 6)
pprt(B, N)
# 3. at least one die shows a one
C <- subset(S, apply(S, 1, min) == 1)
pprt(C, N)
# 4. Intersection of A, B, C
AB <- intersect2(A,B)
AC <- intersect2(A,C)
BC <- intersect2(B,C)
ABC <- intersect2(AB,C)
pprt(AB, N)
pprt(AC, N)
pprt(BC, N)
pprt(ABC, N)
# 5. Union of A, B, C
AuB <- union2(A,B)
AuC <- union2(A,C)
BuC <- union2(B,C)
AuBuC <- union2(AuB,C)
pprt(AuB, N)
pprt(AuC, N)
pprt(BuC, N)
pprt(AuBuC, N)
# 6.
Ac <- setdiff2(S, A); Bc <- setdiff2(S, B); Cc <- setdiff2(S, C)
ABc <- intersect2(A, Bc); pprt(ABc, N)
AcBc <- intersect2(Ac, Bc); pprt(AcBc, N)
ABCc <- intersect2(AB, Cc); pprt(ABCc, N)
ABcC <- intersect2(ABc, C); pprt(ABcC, N)
# Draw a venn diagram
# install.packages("gplots")
library(gplots)
Av <- rownames(A); Bv <- rownames(B); Cv <- rownames(C)
win.graph(7,4); par(mar=c(0,2,0,2))
venn(list(Av, Bv, Cv), showSet=T)
```
{% endtab %}
{% tab title="Result" %}
```
> # 0. Sample Space and Number of Outcoms
> S <- rolldie2(4); N <- nrow(S)
>
> # 1. sum of four dice is greater than or equal to 15
> A <- subset(S, X1+X2+X3+X4 >= 15)
> pprt(A, N)
## P(A) = 575 / 1296 = 0.4436728
>
> # 2. at least one die shows a six
> B <- subset(S, apply(S, 1, max) == 6)
> pprt(B, N)
## P(B) = 671 / 1296 = 0.5177469
>
> # 3. at least one die shows a one
> C <- subset(S, apply(S, 1, min) == 1)
> pprt(C, N)
## P(C) = 671 / 1296 = 0.5177469
>
> # 4. Intersection of A, B, C
> AB <- intersect2(A,B)
> AC <- intersect2(A,C)
> BC <- intersect2(B,C)
> ABC <- intersect2(AB,C)
> pprt(AB, N)
## P(AB) = 453 / 1296 = 0.349537
> pprt(AC, N)
## P(AC) = 140 / 1296 = 0.1080247
> pprt(BC, N)
## P(BC) = 302 / 1296 = 0.2330247
> pprt(ABC, N)
## P(ABC) = 124 / 1296 = 0.09567901
>
> # 5. Union of A, B, C
> AuB <- union2(A,B)
> AuC <- union2(A,C)
> BuC <- union2(B,C)
> AuBuC <- union2(AuB,C)
> pprt(AuB, N)
## P(AuB) = 793 / 1296 = 0.6118827
> pprt(AuC, N)
## P(AuC) = 1106 / 1296 = 0.8533951
> pprt(BuC, N)
## P(BuC) = 1040 / 1296 = 0.8024691
> pprt(AuBuC, N)
## P(AuBuC) = 1146 / 1296 = 0.8842593
> # 6.
> Ac <- setdiff2(S, A); Bc <- setdiff2(S, B); Cc <- setdiff2(S, C)
>
> ABc <- intersect2(A, Bc); pprt(ABc, N)
## P(ABc) = 122 / 1296 = 0.0941358
> AcBc <- intersect2(Ac, Bc); pprt(AcBc, N)
## P(AcBc) = 503 / 1296 = 0.3881173
> ABCc <- intersect2(AB, Cc); pprt(ABCc, N)
## P(ABCc) = 329 / 1296 = 0.253858
> ABcC <- intersect2(ABc, C); pprt(ABcC, N)
## P(ABcC) = 16 / 1296 = 0.01234568
```
* $$P(A∪B) = P(A) + P(B) - P(A∩B)$$ \
$$= 575/1296 + 671/1296 - 453/1296 = 793/1296$$
* $$P(A∪B∪C) = P(A) + P(B) + P(C)$$ \
$$- P(A∩B)-P(B∩C) - P(A∩C)$$ \
$$+ P(A∩B∩C)$$ \
$$= \frac{(575 + 671 + 671)}{1296} - \frac{(453 + 140+302)}{1296} + \frac{124}{1296} = \frac{1146}{1296}$$
{% endtab %}
{% tab title="Venn Diagram" %}

{% endtab %}
{% endtabs %}
1. 补集(Complement)
2. 交集(Intersection)
3. 互斥(Mutually Exclusive)
4. 并集(Union)
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://kmis.gitbook.io/statistics/chapter-3.-basic-concepts-of-probability/3-2.-complements-intersections-and-unions.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.